Ordered UUID 대체 키 사용
깃허브를 돌아다니다 보면 PK로 Auto Increment 나 UUID 를 사용하는 것을 자주 볼 수 있다.
Auto increment를 사용하여 HTTP Method 의 인자로 사용하면 어떤 문제가 일어날 수 있을까?
Auto increment - 예측 가능한 모델이 된다.
Auto increment 로 생성 된 PK를 URL 같은 공개된 장소에 노출시키면
이는 데이터 크롤링이나 인젝션 공격에 조금 더 취약해질 수 있게 된다.
그래서
- Public 공간 - 예측 불가능하고 Random 한 Index 체계 사용
- Private 공간 - Auto Increment PK 값으로 데이터 접근
으로 하는 것이 적절하다.
그러면 오케이 !! UUID 로 값 조회하면 되겠다!
하는데 일반적인 방법으로 UUID 를 조회 기준으로 사용하면 문제가 발생한다.
UUID - 검색 성능이 떨어진다.
UUID 의 구조는 문자열로 이루어져 있다.
💡 UUID 의 구조
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
UUID 에는 "-" 이라는 문자열이 들어가있다.
DB에서 String 데이터로 인덱싱을 하면 어떻게 될까?
인덱스가 비정상적으로 커지고, 검색 성능도 많이 떨어진다.
Binary 값으로 치환해서 저장해야한다.
UUID 는 난수성을 보장받는 체계다
- UUID_1 (처음 생성)
- UUID_2 (두번째로 생성)
- UUID_3 (세번째로 생성)
이 셋은 어떤 순서로 정렬하게 될까?
제프 딘 빼고 아무도 모른다..
그렇다면 문제는?
- 문자열이 랜덤하게 배정되니 데이터 파편화가 되어 인덱싱이 안 된다.
- 순서를 보장 받을 수 없어진다.
- 위 두가지 문제로 DB의 속도가 떨어진다.
https://kccoder.com/mysql/uuid-vs-int-insert-performance/
MySQL InnoDB Primary Key Choice: GUID/UUID vs Integer Insert Performance :: KCCoder
When working with MySQL it is common to choose auto incrementing integer primary keys; however, there are situations where using a GUID/UUID is desirable. For example, prior to MySQL 5.0, you were unable to safely use auto incrementing primary keys in a mu
kccoder.com
그렇다면?
Ordered UUID
Timestamp 기반으로 생성되는 UUID V1 과 완전한 Random 성 UUID V4 를 사용해서 섞어준다.
💡 왜 섞을까?
- UUID V1: Mac 주소 + 타임스탬프(현재시각) 을 이용하여 생성한다.
1. UUID 를 통해 MAC 주소가 유출 될 가능성이 존재한다.
2. MAC 주소와 타임스탬프를 알고 있다면 UUID 를 유추 가능하다.
- UUID V4: 완전 Random 방식으로 생성한다.
1. 생성 원리상 중복 될 가능성이 있다.
2. 근데 중복 가능성이 매~~~~~~~~~우 희박하다.
진짜 초초초초 대용량 데이터가 왔다갔다하는 서비스하면 중복 될 가능성이 오르긴 할테지만, 서비스에 따라서 위 사항을 적용할지 말지 정하면 된다.
UUID V1 생성방식

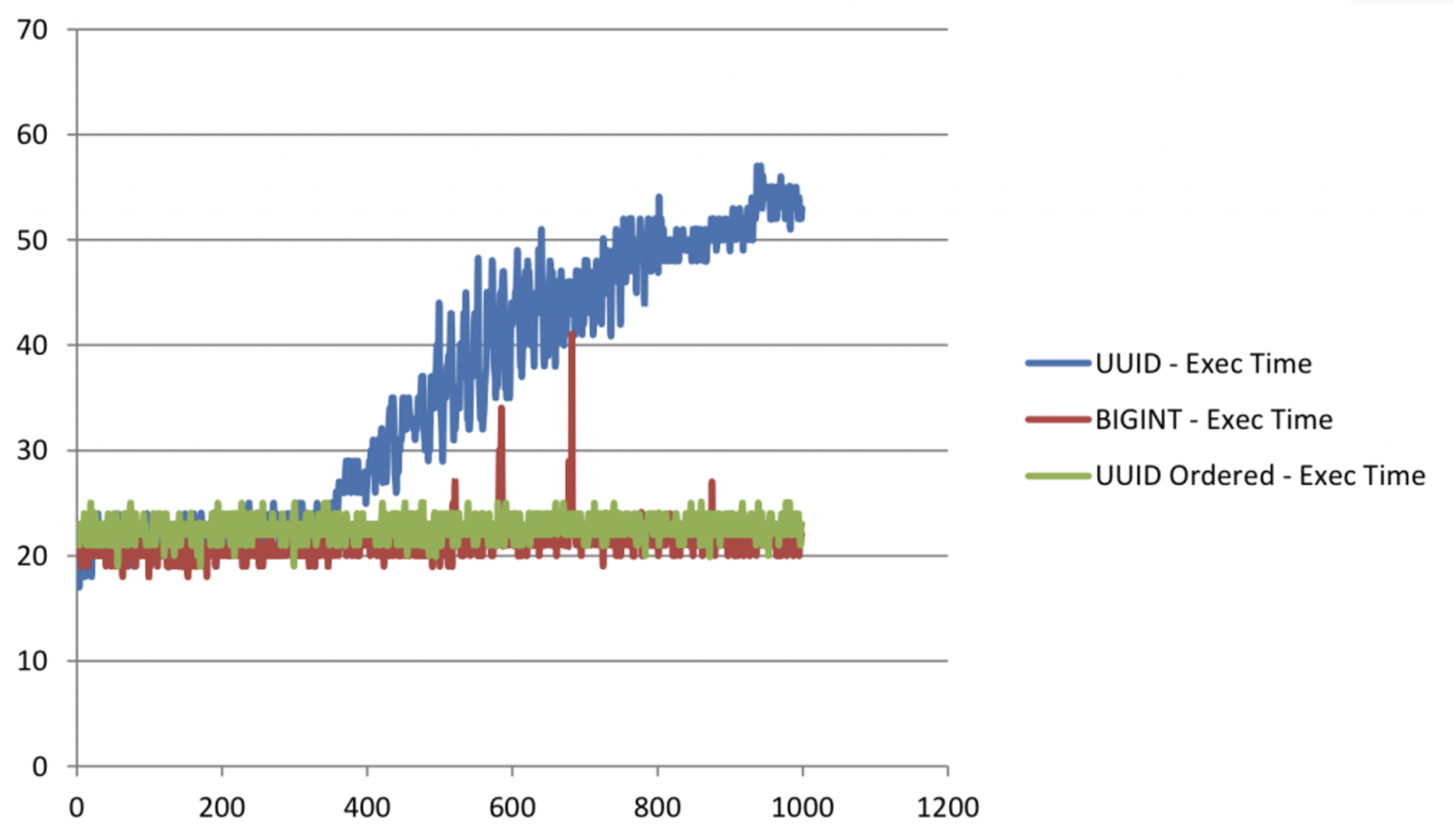
이렇게 하면 Auto increment 로 만든 PK 와 비슷한 수준의 성능을 가질 수 있게 될 것이다.
밑에는 UUID1 만을 기준으로 재정렬한 그래프이다.
- 가로 - Insert 수 x 25,000
- 세로 - 소요시간 (초)
Storing UUID Values in MySQL
Karthik Appigatla revisits a post Peter Zaitsev wrote on UUIDs (Universal Unique IDs), rearranging the timestamp and talks about storing UUID Values.
www.percona.com
이 글이 되게 예전에 올라와서 UUID V1 만을 기준으로 작성됐다.
그래서 UUID V1 의 문제점을 없애려 V4 랑 섞어 쓰는 걸로 개발하면 될 거 같다.
----- 2024.04.21 추가
찾아보니까 ULID 라는 라이브러리, Twitter snowflake, Ksuid 등의 라이브러리들이 있다.
구현방식은 내가 했던 고민들과 거의 일치했다. timestamp 방식으로 64비트 만큼 찍어내고, 뒤에 무작위 64비트 넣는 방식들
여기서 서비스에 따라 전체 바이너리를 128비트로 할지 64비트로 할지 정하는 거 같다.
java util 의 UUID는 UUID V1 만드는 걸 지원하지 않아서, 직접 구현하려고 2일동안 삽질 해봤는데, 아직 내 레벨에서 비트, 바이트 등의 연산은 정말... 어렵다는 걸 깨닫고 라이브러리 사용하는 게 좋을 거 같다는 결론
나중에 레벨 오르면 직접 구현해보고 싶다 허허